这篇Blog分享了我在高级计量经济学课程论文研究过程中从百度地图慧眼抓取省市级人口跨地区迁徙数据和各省市迁徙规模指数数据的过程。
使用提示与重要声明
- 该脚本只是通过正常频率的模拟操作以实现数据的自动获取,调用的是百度地图慧眼的官方API,不对该系统进行任何形式的攻击与破坏;
- 本脚本完全开源,且保证初始参数设置不会对服务器造成显著影响,请在使用脚本的过程中遵守中华人民共和国网络安全法等相关法律法规,请勿通过高频率访问对服务器造成压力过载。因使用者滥用该脚本造成的一切责任,由使用者个人承担;
- 该脚本获取的数据归百度所有,仅限个人科研使用,应数据滥用造成的一切后果由使用者个人承担;
数据来源
因为我在课程论文研究过程中想使用各省市之间的迁徙数据,但没有找到直接的数据文件,但发现百度地图慧眼提供了可视化的人口迁徙图表,其数据页面如下图所示。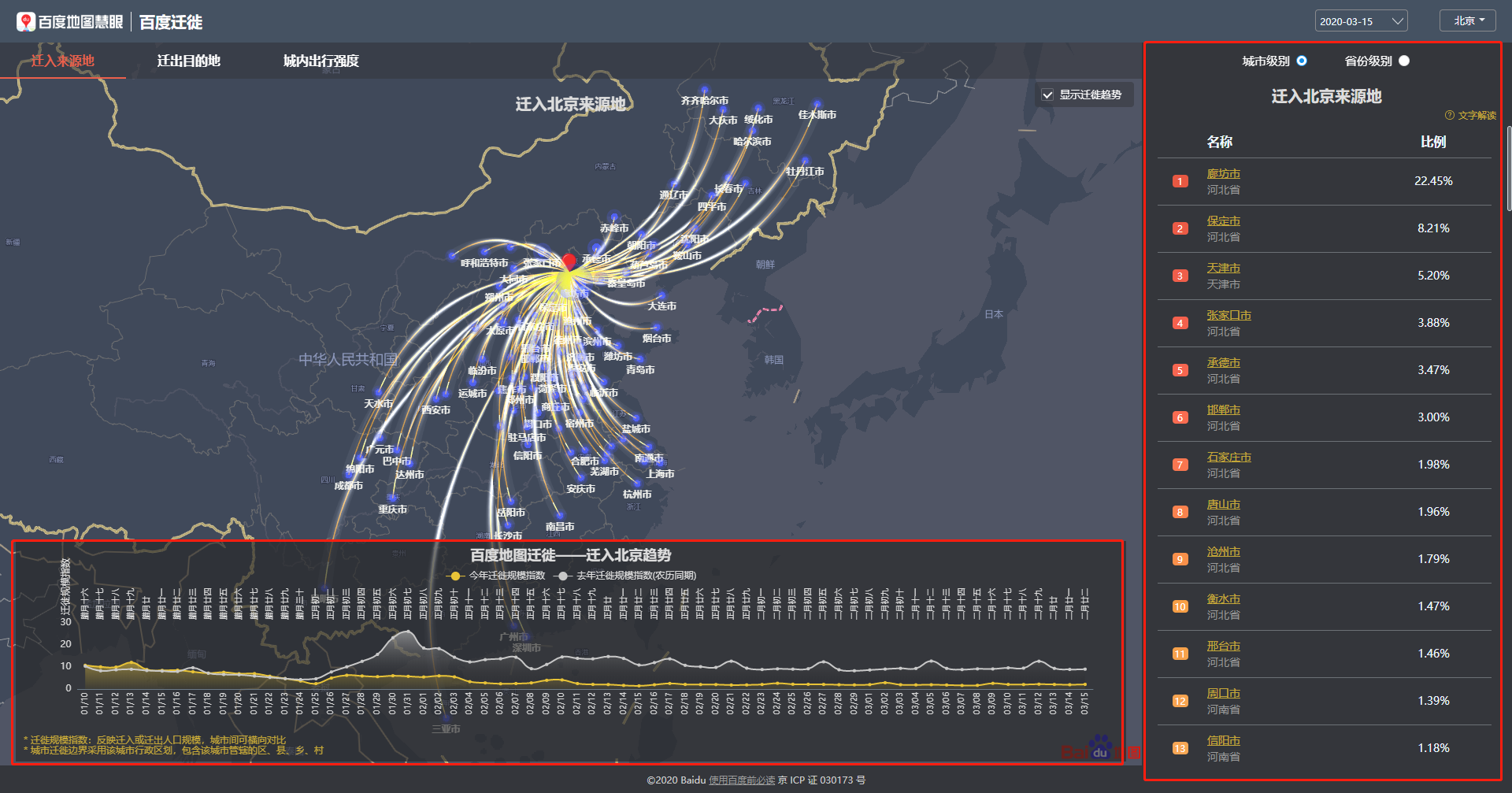
我对页面中两处红框部分的数据比较感兴趣,分别是省级或市级人口跨地区迁徙数据和各省市迁徙规模指数数据,就想着将其原始数据抓取下来。
数据接口
通过分析页面加载过程中传输的数据,获取其数据访问接口。以武汉市为例,获取其2020年2月1日人口迁出到各城市的接口为:
其中dt=city表示市级迁徙数据,id=420100表示武汉市(即武汉市邮政编码),type=move_in表示人口迁出数据,date=20200101表示日期为2020年2月1日。
同理,湖北省2020年2月1日人口迁出到各省市的接口为:
湖北省历史人口迁出规模指数的接口为:
批量获取
既然有了数据获取接口,接下来调用接口并保存数据的过程就比较简单了。在这里给几个简单的小例子。
先导入需要的包,
获取两个日期间的所有日期,以2020年1月10日至2020年3月15日为例,
获取2020年1月10日至2020年3月15日武汉人口跨地区迁徙到各个城市的数据,
获取2020年1月10日至2020年3月15日湖北人口跨地区迁徙到各个省份的数据,
获取上海市历史人口跨地区迁徙迁入规模指数数据,
总结
在计量经济学以及其他许许多多的领域中经常使用到人口迁移数据,非常感谢百度地图慧眼团队提供的细粒度的日度数据,相信会给很多科研人员带来便利,也希望我的小教程能帮到大家!